
Published by: Dikshya
Published date: 24 Jul 2023
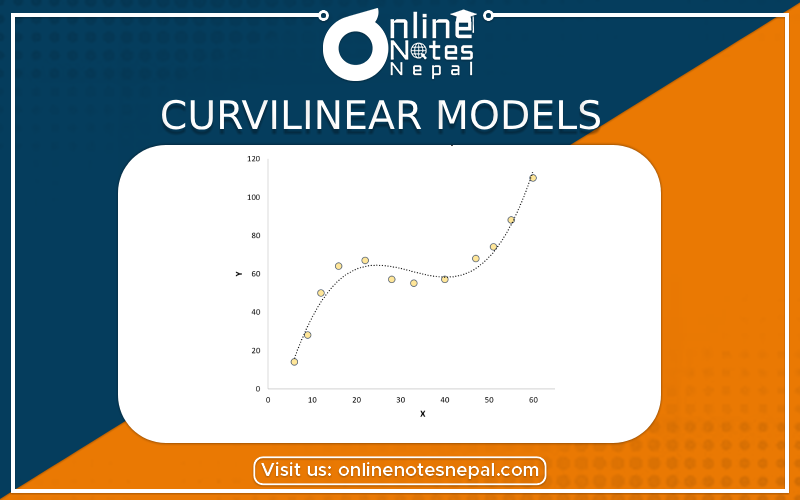
Introduction:
Curvilinear models are a class of statistical models used in data analysis to account for nonlinear relationships between variables. While linear models assume a straight-line relationship between variables, curvilinear models allow for more flexible and complex relationships that can better capture the underlying patterns in the data. These models are particularly useful when the relationship between variables is not linear and when traditional linear models fail to provide an adequate fit.
Types of Curvilinear Models:
Polynomial Regression: Polynomial regression is one of the simplest curvilinear models. It involves fitting a polynomial equation to the data, allowing for curves of different degrees. The general form of a polynomial regression equation is y = β₀ + β₁x + β₂x² + ... + βₙxⁿ, where 'y' is the dependent variable, 'x' is the independent variable, and 'β₀, β₁, ..., βₙ' are the regression coefficients. The degree 'n' determines the complexity of the curve.
Spline Regression: Spline regression divides the data range into smaller segments and fits a polynomial to each segment. The splines are then combined to create a smooth curve that captures the overall trend in the data. This approach reduces overfitting and allows for local adjustments.
Logistic Regression: Logistic regression is a curvilinear model used for binary classification problems. It models the relationship between the independent variables and the probability of a binary outcome. The logistic function transforms the linear predictor into a probability range between 0 and 1.
Exponential Growth and Decay Models: These models describe situations where the dependent variable grows or decays exponentially with the independent variable. Examples include population growth, radioactive decay, and economic growth.
Power Law Models: Power law models describe relationships between variables where one variable changes with a power of the other. The general form is y = β₀x^β₁, where 'x' and 'y' are the variables, and 'β₀' and 'β₁' are the parameters to be estimated.
Model Selection and Evaluation:
Selecting an appropriate curvilinear model involves several steps, including data exploration, visualization, and hypothesis testing. Techniques such as cross-validation and goodness-of-fit measures (e.g., R-squared, AIC, BIC) are used to evaluate the model's performance and compare different curvilinear models.
Challenges and Considerations:
Overfitting: Curvilinear models can be prone to overfitting, especially when the data is noisy or sparse. Regularization techniques and model selection based on cross-validation can help mitigate this issue.
Interpretability: Curvilinear models may be more challenging to interpret compared to linear models, particularly when using higher-degree polynomials or complex splines.
Data Transformations: Sometimes, transforming the data or applying suitable scaling can improve the model fit and aid in interpreting the results.
Conclusion:
Curvilinear models offer a powerful toolset for data analysis, allowing researchers to capture complex relationships between variables that are not adequately represented by linear models. Understanding the underlying patterns in the data and selecting an appropriate model are crucial for obtaining meaningful insights and making accurate predictions. However, it is essential to be cautious about overfitting and to balance model complexity with interpretability based on the specific requirements of the analysis.