
Published by: Sareena Kumari Basnet
Published date: 29 Jul 2024

Recoverability in Database Management Systems (DBMS) refers to the system's ability to recover from failures and maintain database consistency. This is a critical part of database administration that protects data integrity and ensures reliability. Recoverability entails ensuring that transactions are properly managed, such that in the case of a failure, the database can be returned to a consistent state.
Schedules in which transactions commit only after all transactions whose changes they read commit, are called recoverable schedules.

This is a recoverable schedule since T1 commits before T2, that makes the value read by T2 correct.
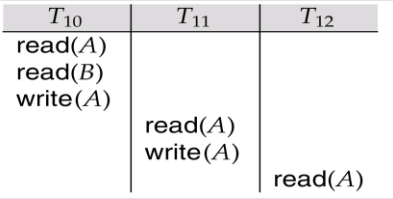
Example:

Logs: Logs are required to provide the recoverability of a DBMS. There are two major types of logs used in DBMS recovery:
Write Ahead Logging (WAL): WAL is an technique that ensures logs are written before data is written to the database. This ensures that even if a failure happens, the logs contain sufficient information to either undo incomplete transactions or repeat completed ones.
Checkpointing: A checkpoint is a method that creates a snapshot of the database at a specific moment in time. Checkpoints help to improve recovery time by limiting the quantity of log data that must be processed. When a checkpoint is performed, the current state of the database and log contents are saved to stable storage. In the event of a failure, recovery can begin from the latest checkpoint, decreasing the amount of effort required to restore the database to a consistent state.
Deferred update: In the deferred update technique, changes made by a transaction are not immediately applied to the database. Rather, they are documented in a log. The database is only updated when the transaction reaches its commit point. This ensures that no changes are made to the database until the transaction is confirmed as successful.
Immediate update: In the immediate update technique, changes made by a transaction are immediately applied to the database. However, if a transaction fails before committing, the system must undo the modifications to ensure consistency. This necessitates meticulous tracking of before and after photographs of the data elements.
Shadow Paging: Shadow paging maintains two copies of each database page: the current page table and the shadow page table. The current page table is updated, while the shadow page table is left unaltered. When a transaction is committed, the current page table is written to disk, which replaces the shadow page table. If a failure occurs, the system can resort to the shadow page table to keep the database consistent.
Transactional Failures: Transactions fail because of logical problems (such as division by zero) or system faults (such as deadlocks). When a transaction fails, the system must ensure that the database is restored to its former consistent state by utilizing the undo log.
System failures: System failures are caused by hardware or software errors that lead to the loss of the system's volatile memory. During recovery, the system uses the logs to return the database to a consistent state.
Media Failures: Media failures occur when the storage media is physically damaged, resulting in the loss of data. Recovery from media failures usually entails restoring data from backups and applying logs to keep the database up to date.